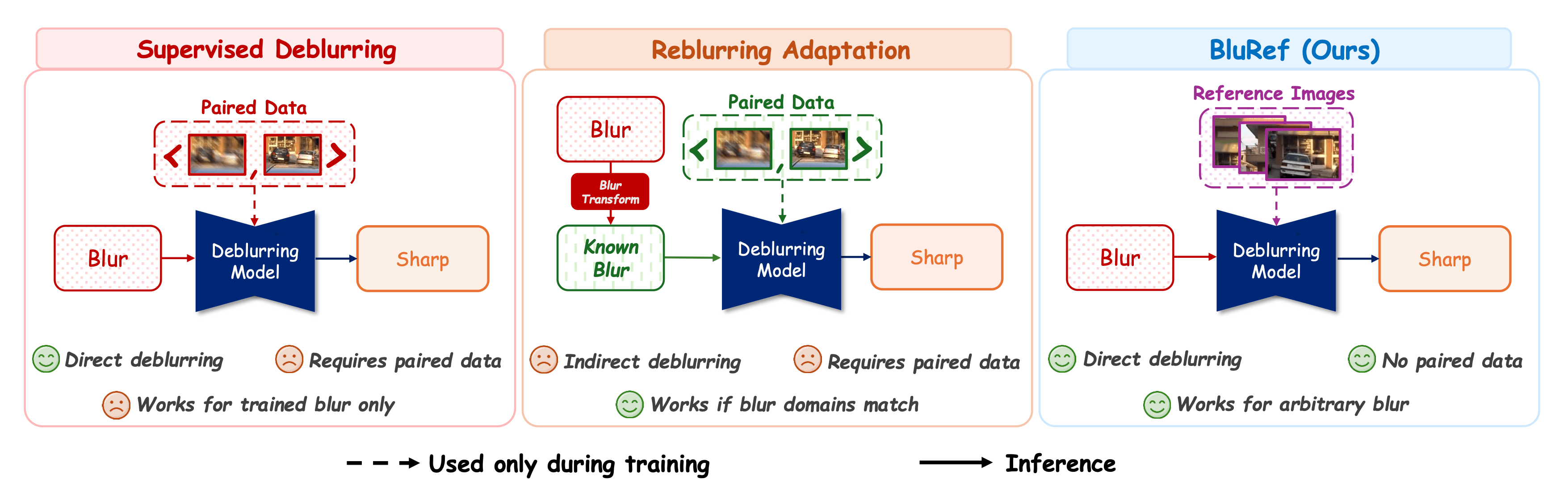
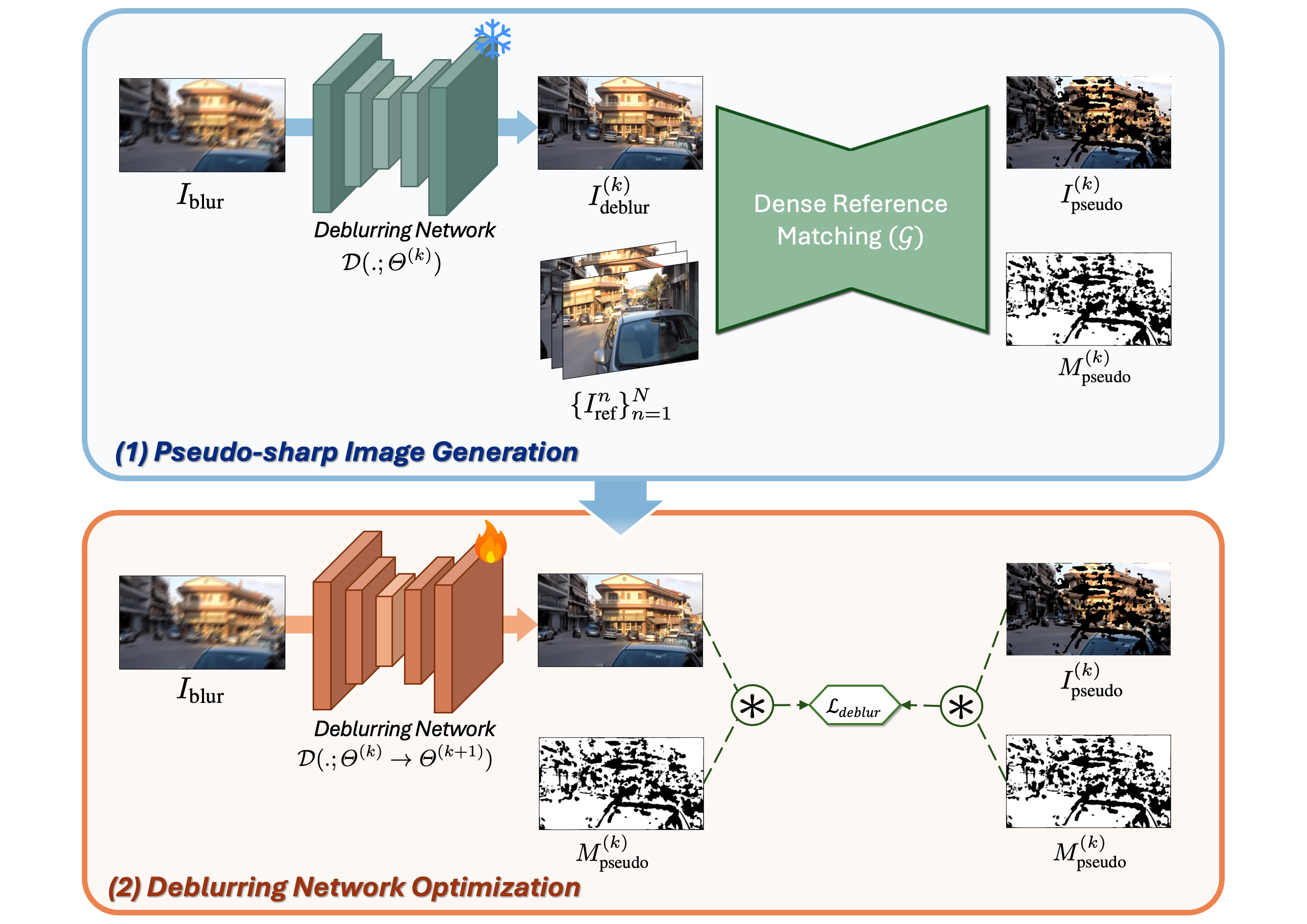
Real-World Generalization
PhoneCraft — Can BluRef Handle Fully Unpaired Real-World Data?
❓
Can BluRef generalize to fully unconstrained real-world settings
where blurry and sharp data come from completely separate, unsynchronized recordings?
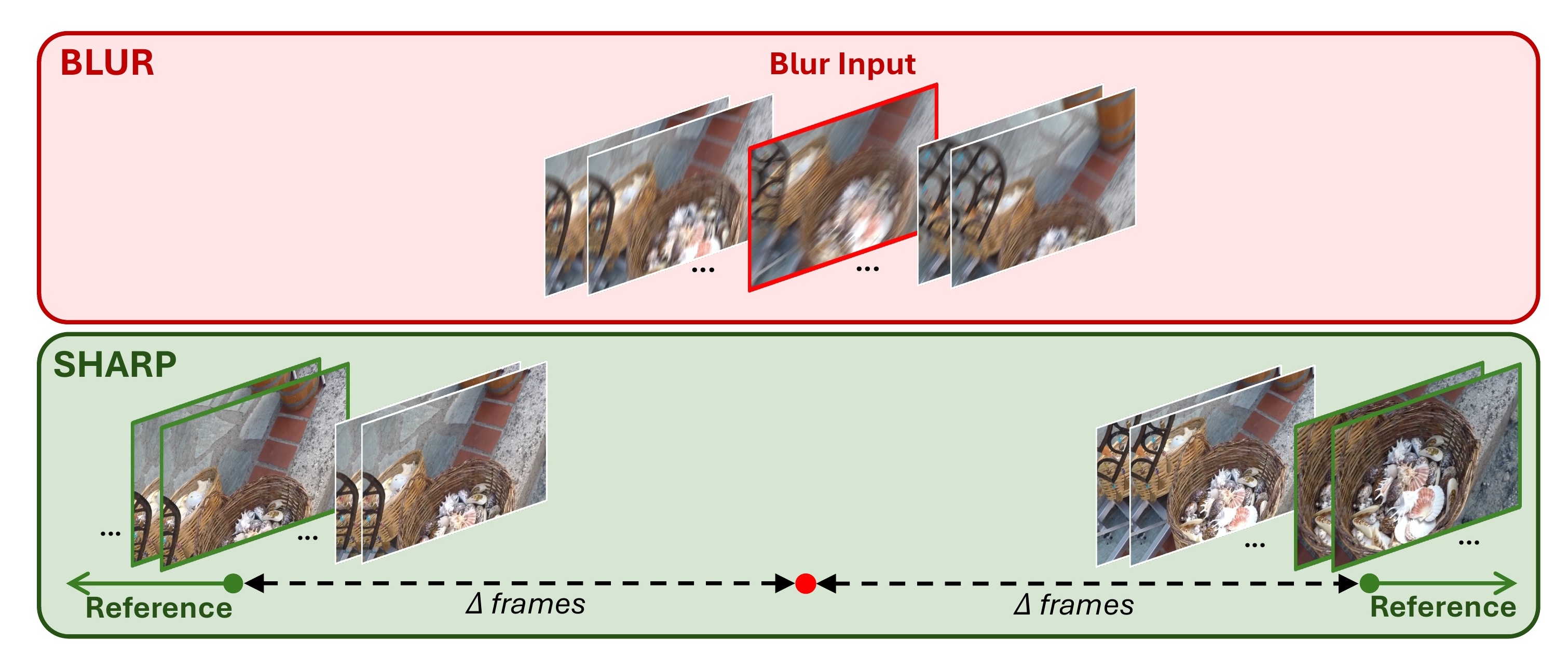
Why PhoneCraft matters: PhoneCraft is a challenging real-world benchmark
consisting of 12 blurry and 11 sharp video clips (30–40 seconds each, 60fps) recorded
by a handheld smartphone in unconstrained environments.
Unlike GoPro and RB2V, PhoneCraft has no paired ground truth and
no temporal alignment between blurry and sharp clips at all.
Blurry frames arise from rapid camera or object motion, while sharp clips are captured
when the camera is mostly static. References are randomly selected from separate
sharp clips for each blurry input, eliminating any temporal correlation.
This experiment directly demonstrates BluRef's practicality: it confirms that our method
works with separate, unsynchronized sharp and blurry videos — a setting
that is trivially easy to collect in practice, requiring no special equipment or controlled conditions.
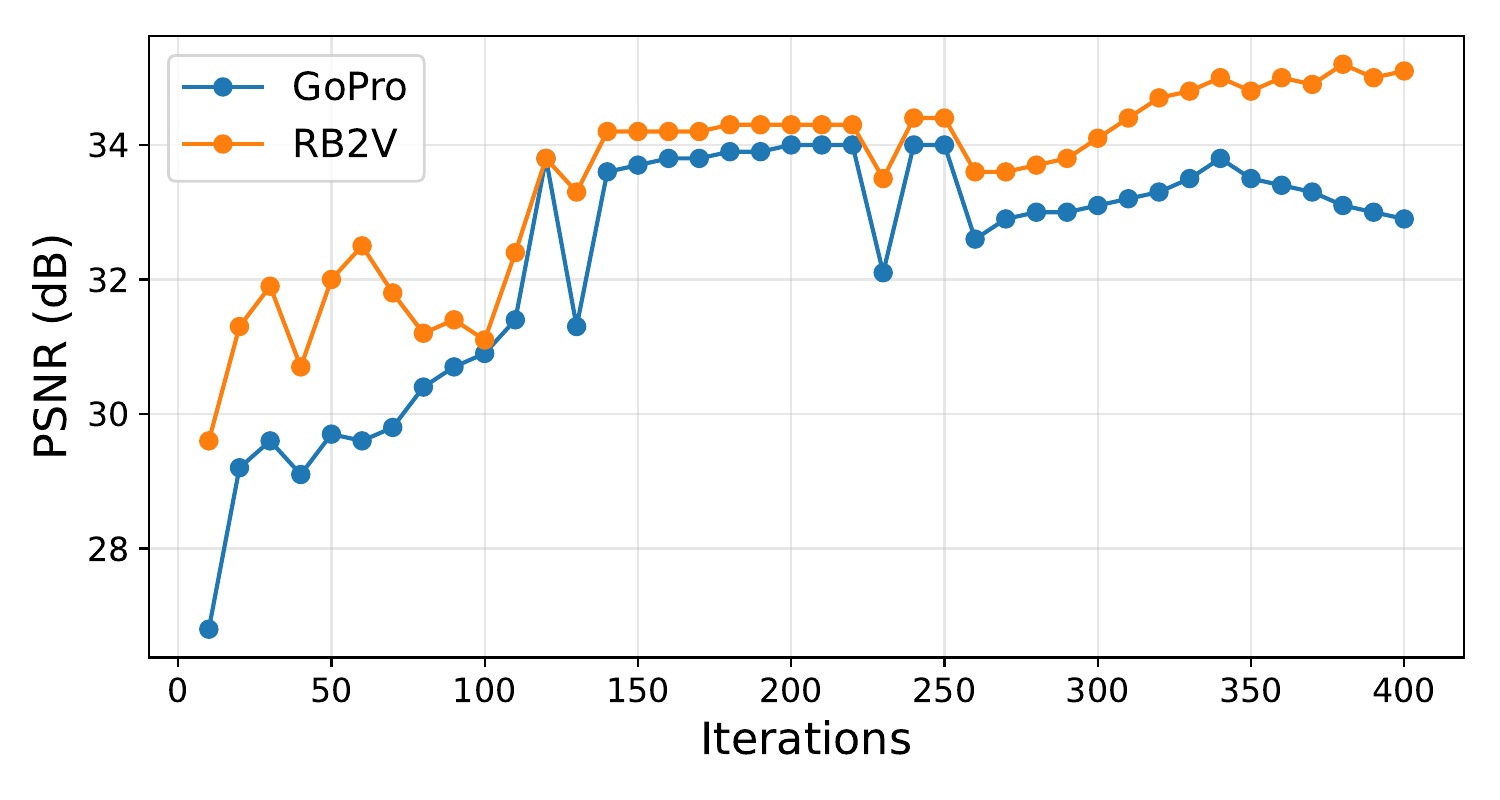
🏅 Why Does Unsupervised BluRef Surpass Supervised Models?
Supervised models are fundamentally limited by the fidelity of their ground-truth labels.
Even when paired data can be collected using specialized hardware, the resulting "sharp" labels
are rarely perfect. On RB2V, hardware limitations introduce residual blur into the
ground-truth images, causing supervised models to overfit to these imperfect labels.
In contrast, BluRef leverages external sharp reference frames
— which can be cleaner than the hardware-limited ground truth — to generate pseudo-sharp
supervision that exceeds the quality of available labels. This advantage is further
demonstrated on PhoneCraft, where no ground truth exists at all: supervised baselines
struggle while BluRef continues to generalize effectively.
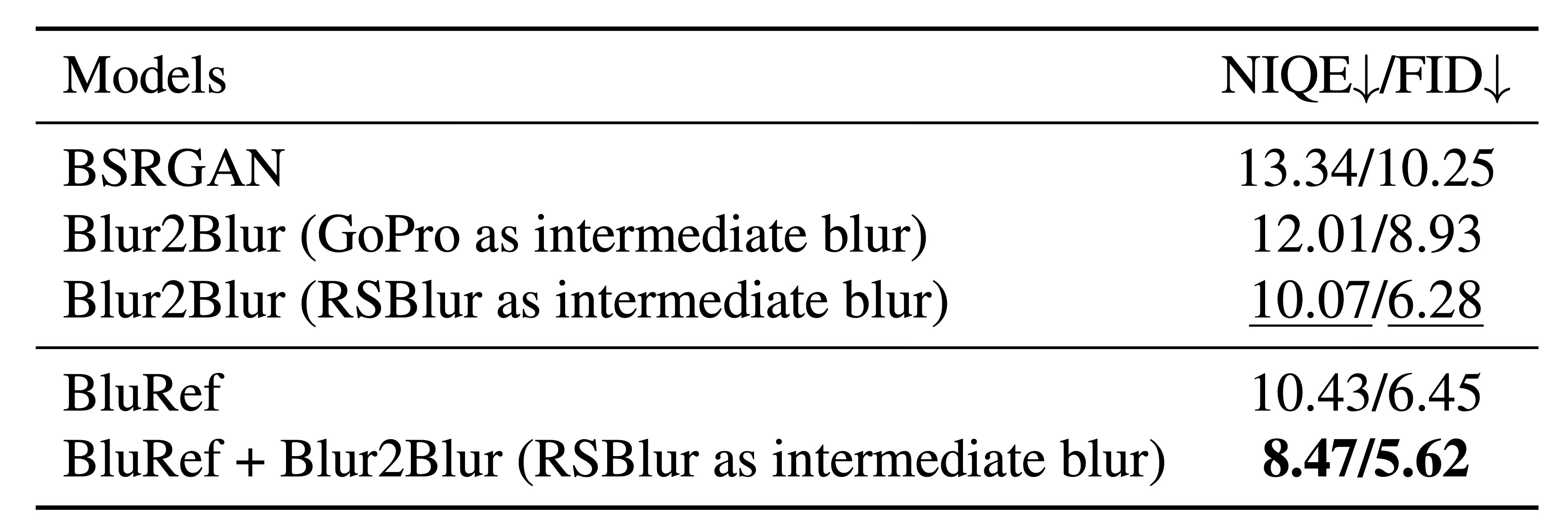
As shown in Table 5, our unsupervised framework (BluRef + Blur2Blur) outperforms supervised models
on both GoPro and RB2V — proving that reference-based pseudo-GT can overcome the ceiling
imposed by imperfect paired data. See the qualitative comparison below: