Method
We model the policy as p(at, dt | ot, St, l), where in addition to the action at the model also emits a language description dt that updates a scratchpad St = {d1, …, dn}. The scratchpad has three sections:
- Grounding — initialization conditions: object positions, end-effector position. Provides spatial memory.
- Plan — the sub-tasks the model must complete to solve the task.
- Act — the sub-tasks completed so far. Provides temporal memory.
The scratchpad is updated whenever the model emits a special
<done> token marking the end of a sub-task. The same recipe
applies to both transformer VLAs (T-VLA, built on PaliGemma-2)
and recurrent VLAs (R-VLA, built on Mamba), with the recurrent
variant interleaving instructions, observations, actions, and descriptions into
a single sequence trained with next-token prediction.
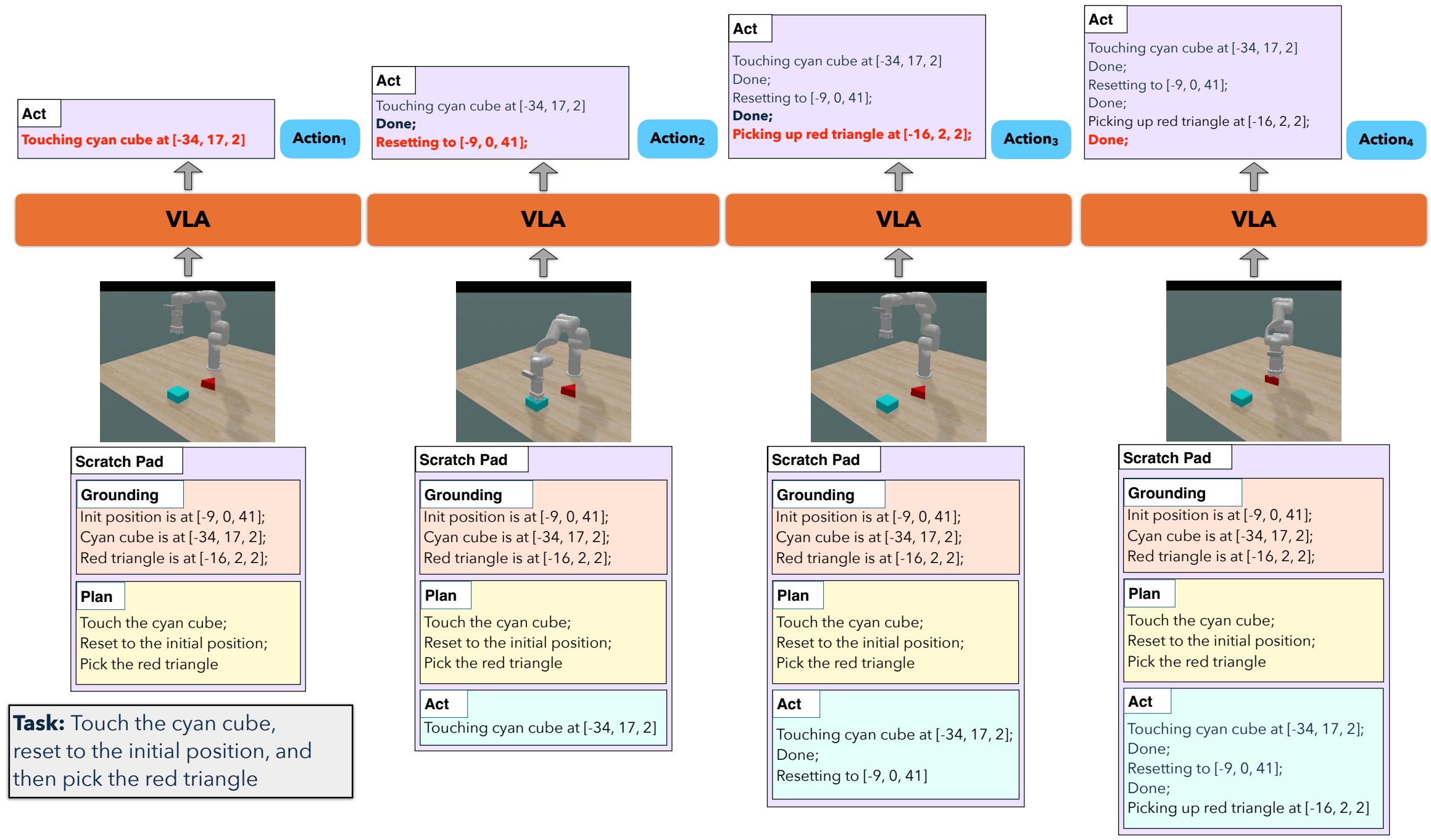
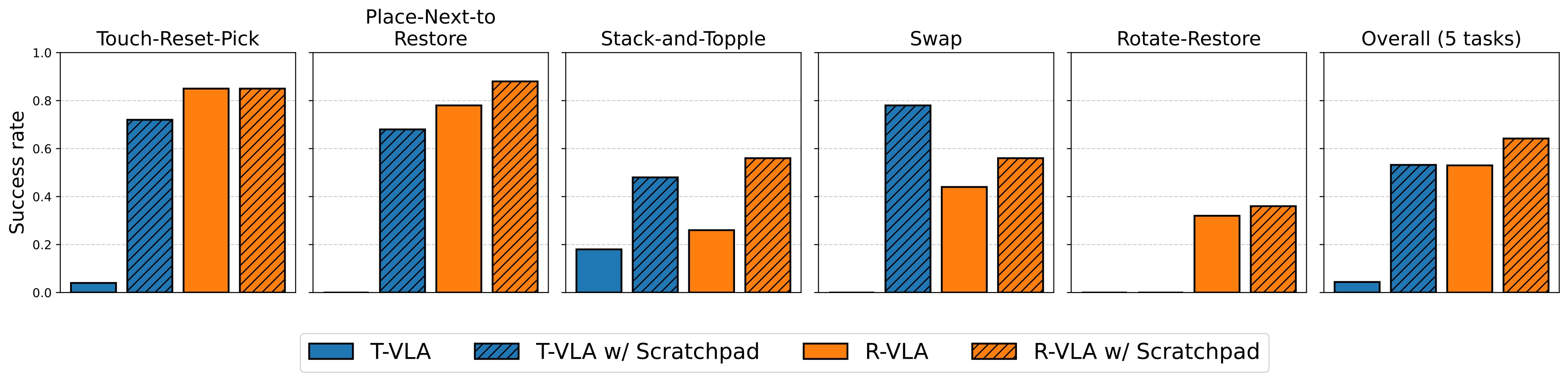
Results on ClevrSkills-Mem
Policy rollouts of our scratchpad-augmented VLA on each ClevrSkills-Mem task.
Real-World Rollouts
Real-world rollouts on Pick-Place-Restore: the robot must pick a tomato, place it in a bowl, and restore the tomato to its original location. Setup is a UFactory xArm 6 with a flexible two-fingered gripper and a single RealSense D435 camera. Models are LoRA-finetuned from pretrained OpenVLA on 200 tele-operated demonstrations. Without the scratchpad, the baseline picks the tomato but cannot tell whether it should next place it in the bowl or restore it — the start and end states look almost identical.
| Model | Avg. Success | Sub-task CR | Avg. Restore Distance |
|---|---|---|---|
| Human teleop | 100% | 3.0 | 3.2 cm |
| OpenVLA | 0% | 0.9 | — |
| OpenVLA + Scratchpad (ours) | 65% | 2.4 | 10.62 cm |
Results over 20 rollouts per model on Pick-Place-Restore.