Abstract
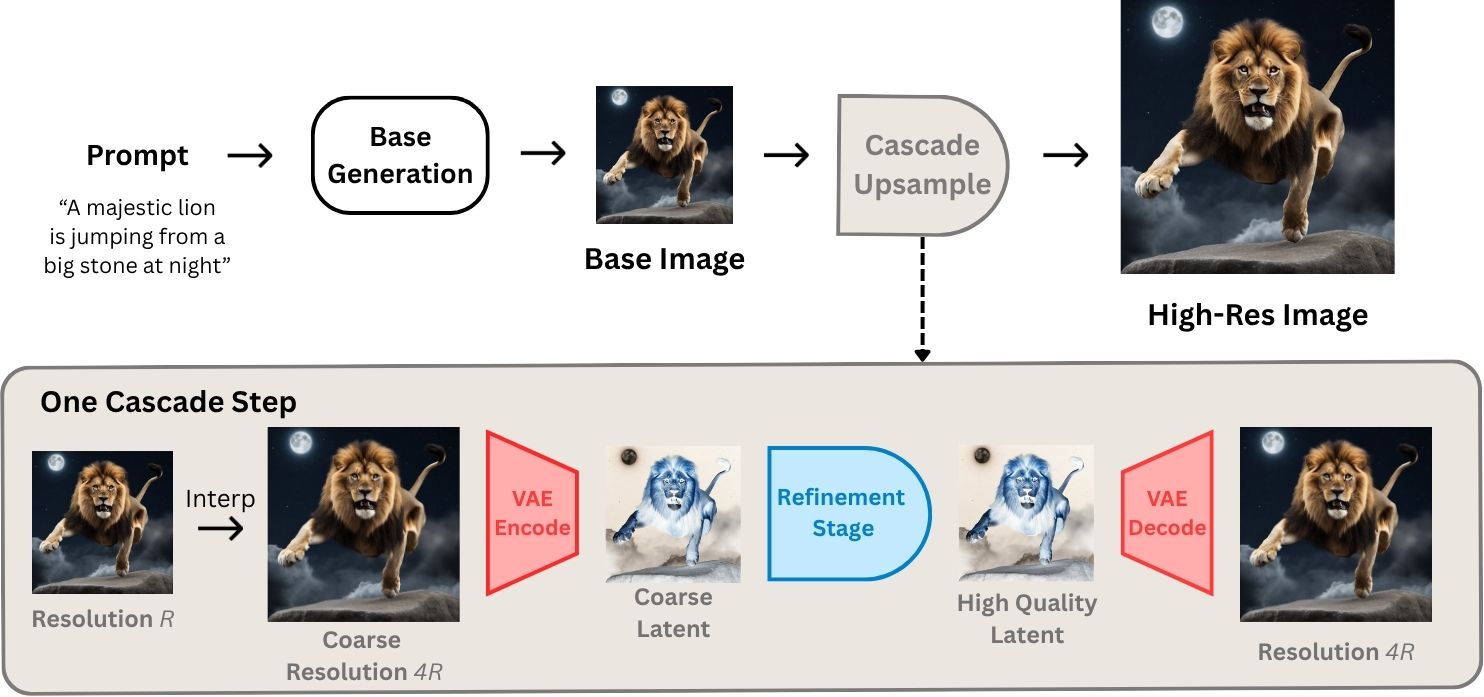
Pre-trained diffusion models excel at generating high-quality images but remain inherently limited by their native training resolution. Recent training-free approaches have attempted to overcome this constraint; however, these methods incur substantial computational overhead, often requiring more than five minutes to produce a single 4K image.
We present PixelRush, the first tuning-free framework for practical high-resolution text-to-image generation. Our method builds upon patch-based inference but eliminates multiple inversion-regeneration cycles. Instead, PixelRush enables efficient patch-based denoising in a low-step regime. To address artifacts from few-step patch blending we propose Gaussian feathering; to combat oversmoothing we introduce a noise injection mechanism.
PixelRush generates 4K images in approximately 20 seconds — a 10–35× speedup over state-of-the-art — while maintaining superior visual fidelity across all quantitative metrics.