Key Contributions
Anti-I2V consists of three core components that jointly enable powerful, robust, and effective protection across diverse video diffusion backbones.
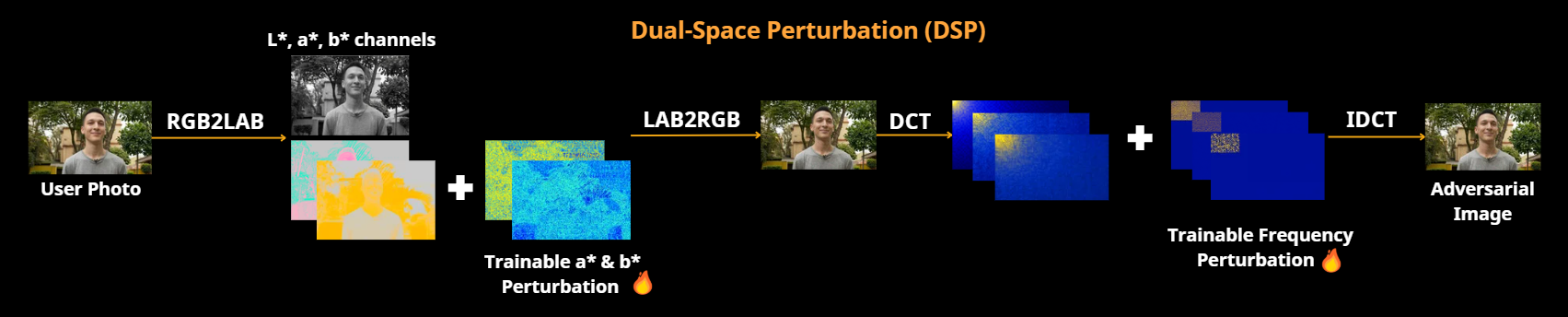
We propose a robust perturbation strategy that goes beyond the standard RGB space, which has been shown insufficient against modern video diffusion models. Anti-I2V's DSP operates in two complementary domains: (1) the L*a*b* color space, applying adversarial noise exclusively to the perceptually decorrelated a* and b* channels; and (2) the DCT frequency domain, targeting the most influential low-frequency components that encode fundamental structural and textural information. This dual-space approach yields perturbations that are simultaneously more effective at disrupting feature propagation, less perceptible spatially, and more resilient to common transformations such as blurring and JPEG compression.
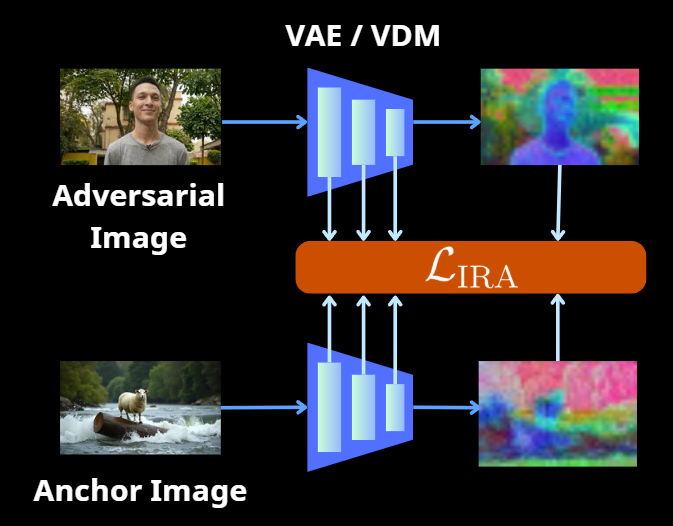
We propose the Internal Representation Anchor (IRA) loss, which minimizes the layer-wise Euclidean distance between hidden features produced when conditioning on the perturbed image versus an unrelated target image, across both the denoising network and the VAE. Unlike prior methods (e.g., AdvDM, MIST) that focus solely on the final output of the VAE, IRA disrupts feature extraction at every intermediate layer of all model components. This prevents the reconstruction of meaningful structure throughout the denoising process, amplifying the adversarial effects.
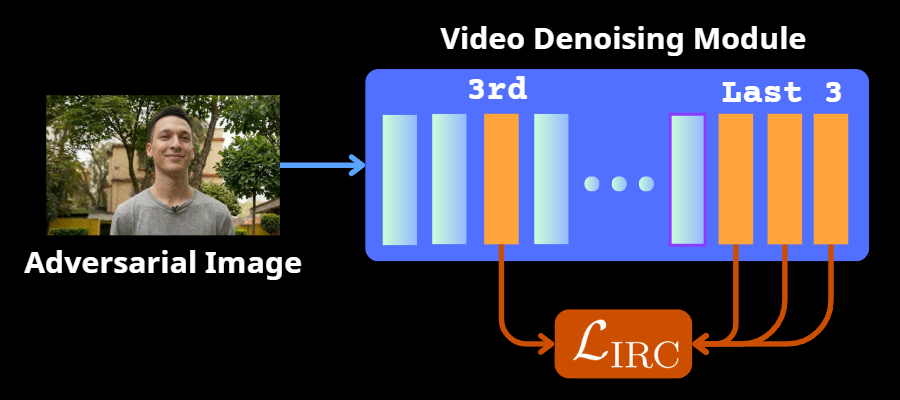
Using PCA visualization of transformer block outputs during the denoising process, we identify that semantically rich features emerge in deeper layers (e.g., layer 27+ in CogVideoX, layer 19+ in OpenSora), while early layers (e.g., layer 3) contain minimal semantic information. The IRC loss forces deep-layer feature maps to resemble those of the early low-semantic layer, collapsing high-level semantic representations throughout the module. This cascades through the attention mechanism, degrading semantic coherence and visual continuity in generated videos.