Motivation
The Identity Crisis in Multi-Human Generation
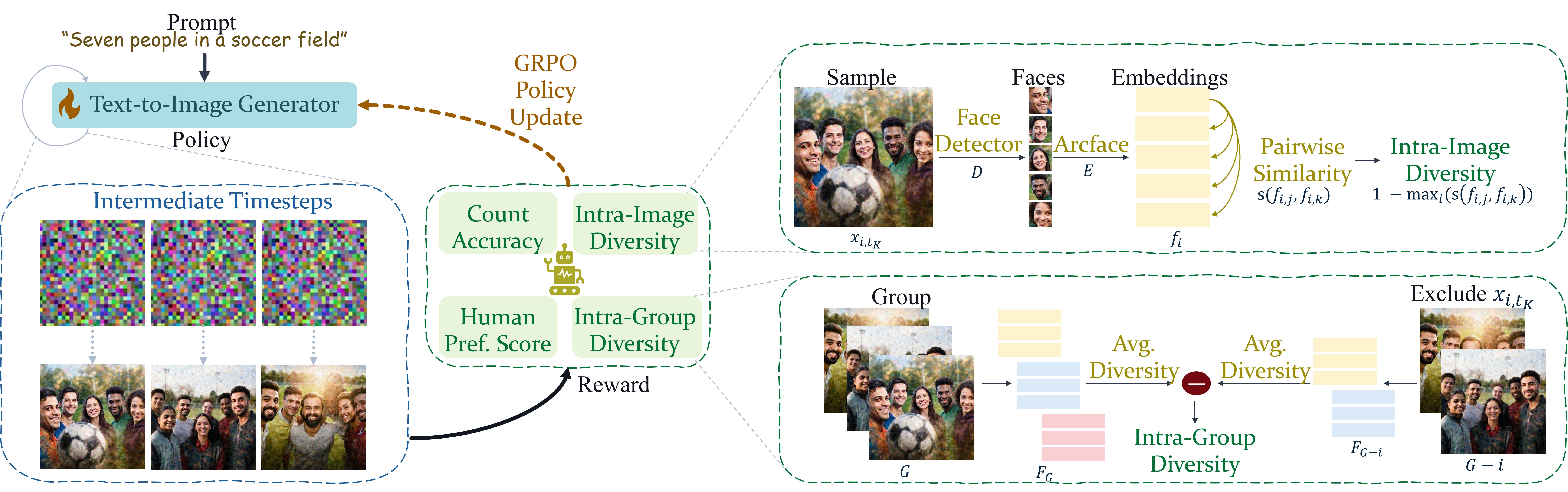
Modern text-to-image models produce strikingly photorealistic imagery—but ask them to render a group of people and they consistently fail: faces are duplicated, individuals look eerily identical, and the requested headcount is wrong. We call this the identity crisis.
This severely limits real-world applications: synthetic data for group photo personalisation, consistent character storytelling, narrative media, educational content, and social simulation all require reliably different people in every scene.

Fig 1. State-of-the-art text-to-image models frequently generate near-identical faces when prompted for multiple people, even when overall image quality is high. DisCo eliminates these failures.